LearnSpark
Polardb-x 的 join 实现
文档信息提取
https://developer.aliyun.com/article/783392 本文首先介绍了 MySQL 的 join 实现,包括以下方式
- Nested-Loop Join (NL Join)
- Batched Key Access Join (BKA Join)
- Block Nested-Loop Join(版本 < 8.0.20)
- Hash Join (版本 >= 8.0.18)
polardb-x 支持多种 join 方式,包括 Lookup Join、Nested-Loop Join、Hash Join、Sort-Merge Join 等,本文主要讲的是 Lookup Join
lookup join
Lookup Join 的执行过程如下(非索引回表情形):
分布式 join 调研
分布式 join 调研
Citus Data
Citus Data 是一个开源的分布式数据库管理系统,它是基于 PostgreSQL 架构之上,能够允许数据库在多个服务器之间进行分布式运算,以便应对大型数据处理和高流量负载的需求。利用 Citus Data 可以为 PostgreSQL 提供横向扩展的能力,使其可以更好地应对应用中的大量数据请求,具有较高的性能和可扩展性。Citus Data 的特点还包括良好的可用性、容错性、可管理性和可扩展性。Citrus Data 可以作为云端数据库的解决方案提供,同时也适用于在本地运行的企业数据库和分析场景中。
分布式 join 支持方式(数据复制)
单表 join 分表
下图介绍了 单表和 sharding 表 join 时 citus 的处理方式
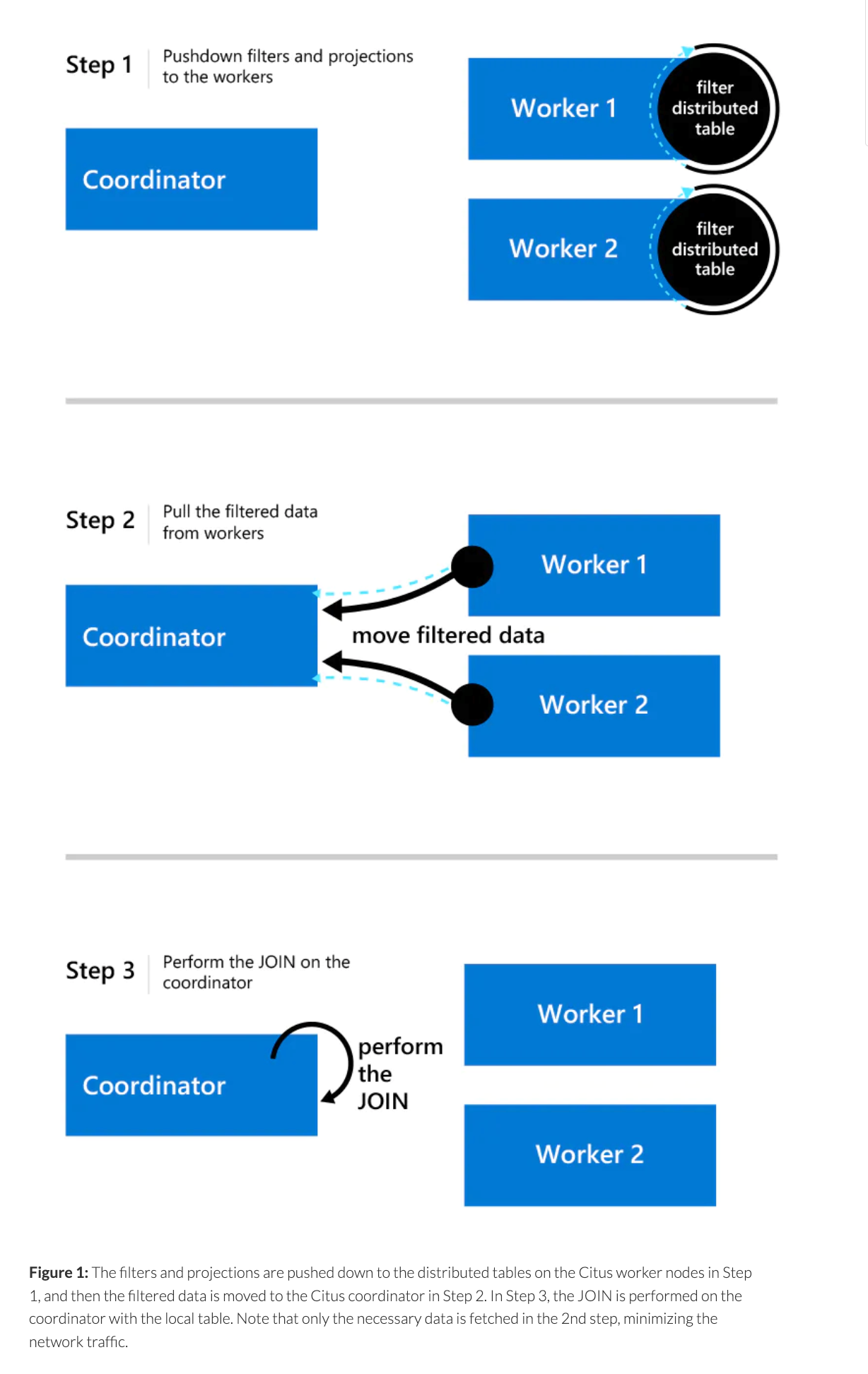
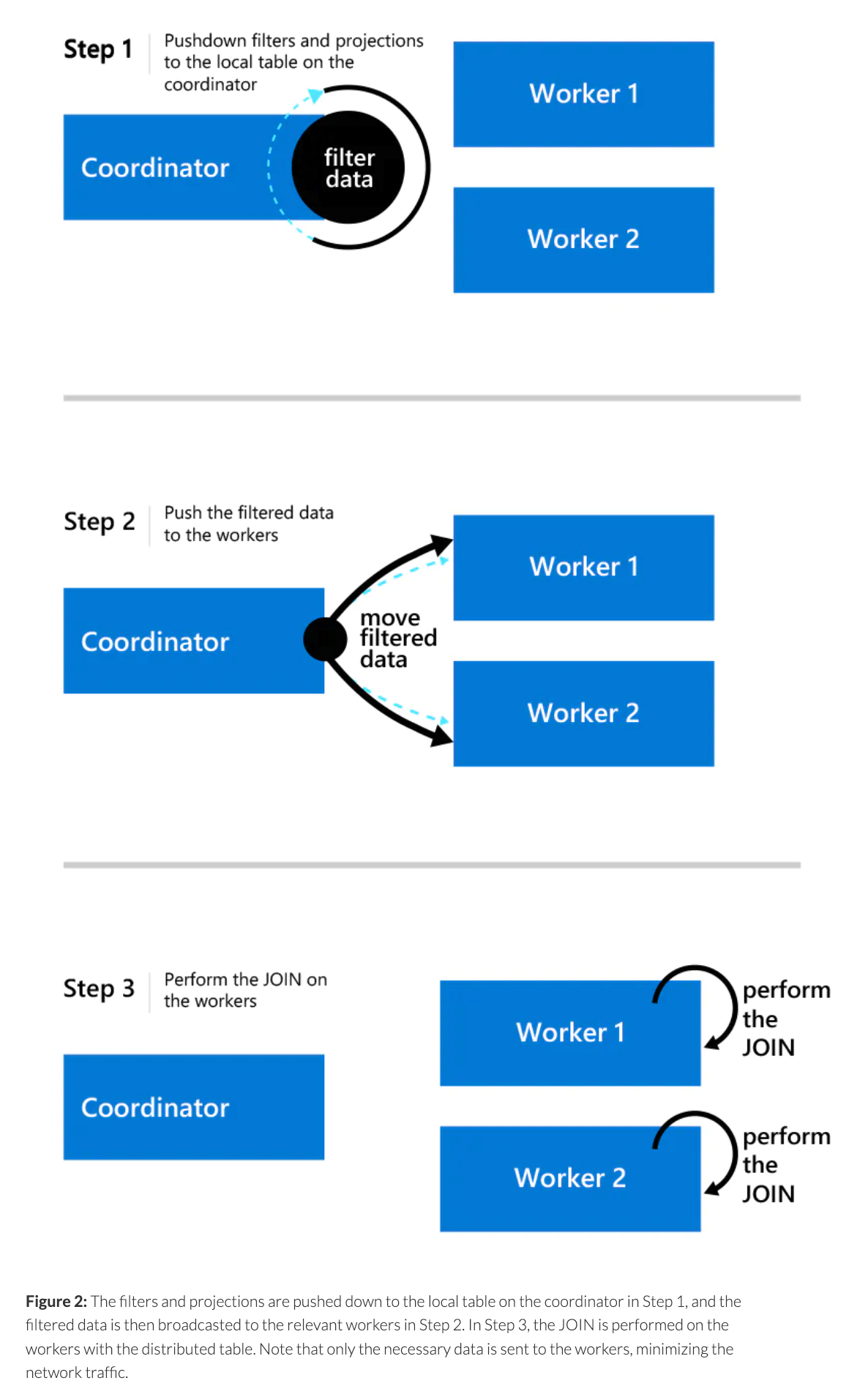
它两种方式来对 local 表和 distributed 表进行关联查询
- 将 distributed 表的数据从 workers 节点移动到协调器
- 将 local 表数据从协调器移动到 workers 节点
两种方式的选择有多种模式可以配置,例如自动模式: 因为一般来说 distributed 表的数据量比较大,所以只有当满足以下条件时才会将数据从 distributed 移动到 local 中
ShardingSphere 元数据能力增强解读与实战
Apache ShardingSphere 元数据介绍
Apache ShardingSphere 的元数据主要包括规则、数据源、表结构等信息。规则信息可能包含分片、加密、读写分离、事务、高可用等。 数据源信息存储的是需要通过 ShardingSphere 来进行管理的底层数据库资源。表结构信息主要就是底层数据源的表结构,包括表的 column 信息、索引信息等。
Apache ShardingSphere 通过这些元数据信息配合治理中心的能力,例如 zookeeper、etcd 的存储和通知能力,可以实现集群内配置的共享和变更,从而实现计算节点的水平扩展。同时元数据信息对于 ShardingSphere 而言也是至关重要的,以表的数据结构为例,ShardingSphere 利用表的数据结构可以对采用了加密规则的 SQL 进行正确的改写,内核中的 federation 引擎也会利用表结构信息进行 SQL 优化。
既然 ShardingSphere 的元数据如此重要,那么我们该怎么入手了解元数据呢?
Apache ShardingSphere 三层元数据结构
ShardingSphere 的三层元数据结构是个了解元数据信息的很好入口。我们可以启动 ShardingSphere–proxy 的 cluster 模式,这样可以在 zookeeper 中直观的看到 ShardingSphere 的三层元数据结构。 如下结构展示了 ShardingSphere 元数据在 zookeeper 中的结构