Tech
背景
用户使用 shardingsphere 发现 No suitable driver 异常。但是用户的 jar 包中是有该驱动的。
调查
发现如果增加这段代码后,可以正常执行
1
Class . forName ( "com.mysql.cj.jdbc.Driver" );
正常而言,按照 JDBC4.0 标准,驱动是通过 spi 机制加载。不需要手动加载。
通过 debug DriverManager 发现其中有个驱动的名称中包含了 - 不是合法的 java 名称。
但是会将异常吞掉,所以没有展示出来。
修复名称后,可以正常使用。
相关知识
JDBC4.0 是通过 spi 加载。
- 不是合法名称,使用 shade 插件替换名称时要注意。
DriverManager 加载多个驱动过程中,如果有任何一个失败,都不会再继续加载,并不会抛出相关异常。
https://github.com/julianhyde/sqlline
sqlline 是一个通过 jdbc 的连接工具。
下载代码并编译
git clone git://github.com/julianhyde/sqlline.git
cd sqlline
./mvnw package
将 shardingsphere-jdbc 打包,之后最好再使用 sharde PLUGIN 打成一个 jar 包
修改 sqlline bin 目录下的 sqlline 脚本,将相关依赖添加进去包括数据库驱动、shardingsphere shade jar、 sqlline-VERSION-jar-with-dependencies.jar
#!/bin/bash
# sqlline - Script to launch SQL shell on Unix, Linux or Mac OS
BINPATH=$(dirname $0)
exec java -cp "$BINPATH/../target/*":"/Users/chenchuxin/Documents/sqlline-sqlline-1.12.0/bin/*" sqlline.SqlLine "$@"
# End sqlline
使用 sqlline
sqlline -d org.apache.shardingsphere.driver.ShardingSphereDriver -u jdbc:shardingsphere:absolutepath:/Users/chenchuxin/Documents/GitHub/sw-test/src/main/resources/META-INF/oracle.yaml
Tech
初步了解 opendal
查看 examples
了解到 opendal 是各种数据源的通用连接器
运行接入到 mysql 试试看
查看 good first issue 的相关 pr
Tech
如何才能实现分布式 join?
有三种方式:
将数据全部抽取到内存中,进行内存计算。
将数据全部抽取到一个数据源中,直接进行查询。
内存和存储并用。
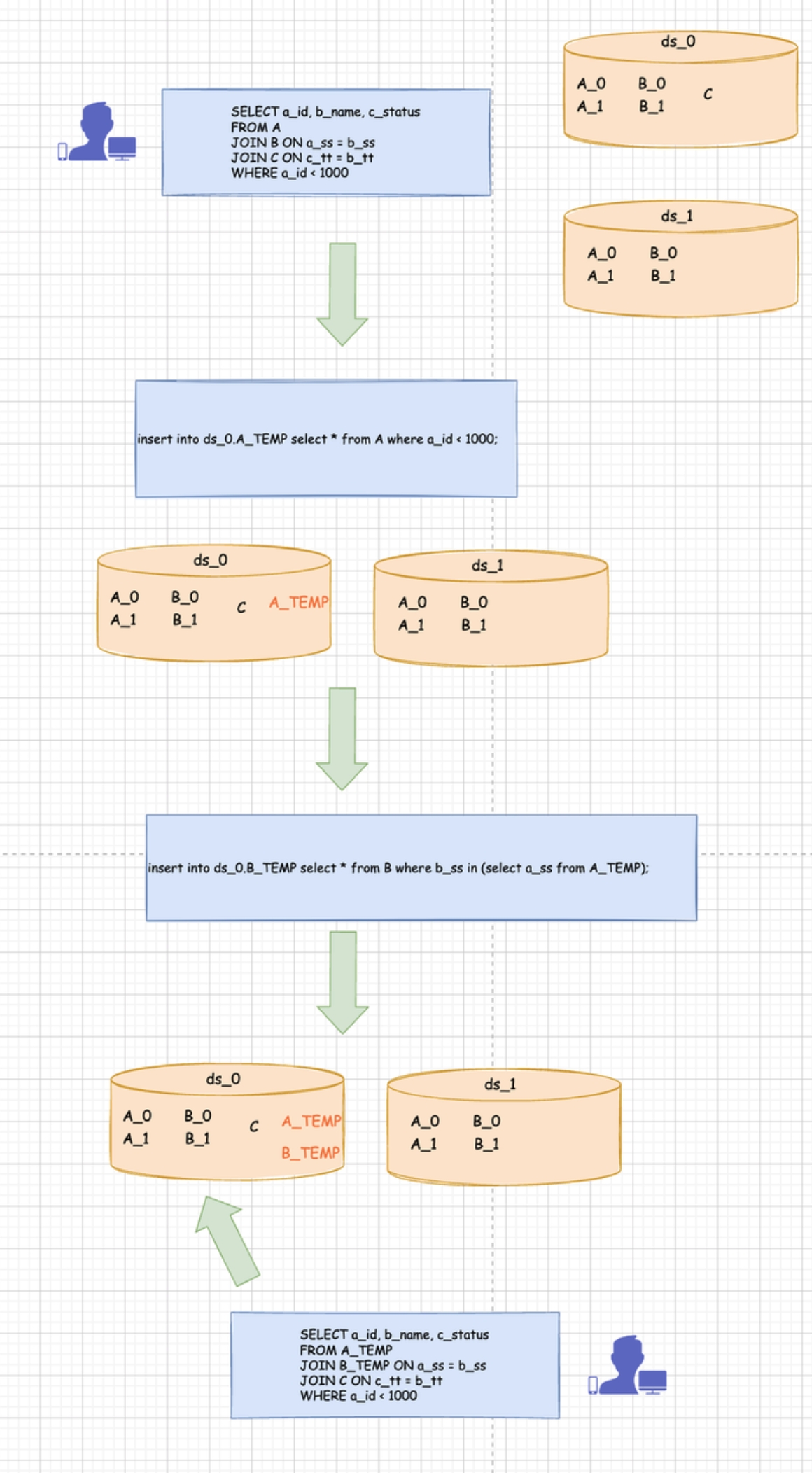
对于分析型的 SQL 而言,不需要考虑事务和性能的话,可以采用数据挪动的方式来实现。
如下图所示,列出了可能的实现方式。
该方案的具体实现需要考虑 2 点。
语义分析 (考虑通过 calcite 或者自行解析提取条件)
获取表之间的依赖关系,例如 A left join B on condition,那么 B 依赖 A, 可以先将 A 抽取出来,再依据 A 来抽取 B
增加条件到表中
支持数据迁移(需要支持数据迁移的管理)
Tech
Target
说清楚 calcite 是什么,能做什么
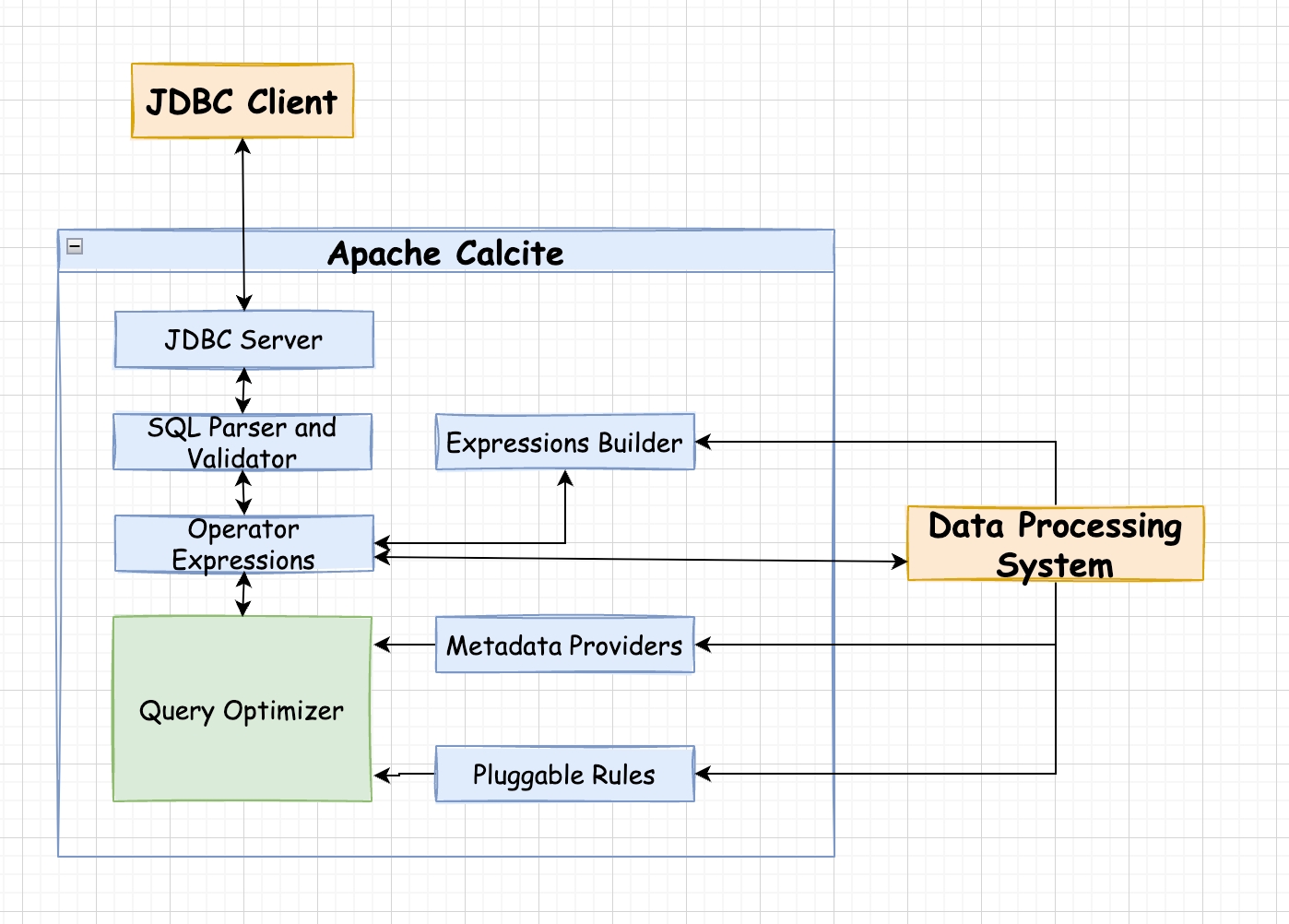
画出 calcite 的大体架构
明白 calcite 是如何跟 SS 整合的
未来 SS 还可以在哪些方面进一步利用 calcite
calcite 优化逻辑源码级理解
在 calcite 上提交 pr
Process
calcite 是什么,能做什么
calcite 是动态数据的管理框架。我理解,就是数据库的计算层,去除掉了存储的部分。
calcite 可以接入任何形式的数据,只需要我们将数据注册成表的形式,那么就可以使用 SQL 来对它进行查询。
calcite 的大体架构
calcite 如何跟 SS 整合
ShardingSphere 可以支持分库分表,所以也自然会有跨实例查询的 SQL。 例如跨实例的 join。这些 SQL 是没办法直接下推到数据库去执行的,因此利用 calcite 来实现复杂子查询或者是跨实例 join。
我们可以从一个跨实例 join 的 select debug 来查看整合 calcite 的方式。
1.
执行查询前,会先构造 OptimizerContext,里面包含一些数据库的配置,例如
caseSensitive -> false
conformance -> MYSQL_5
timeZone -> UTC
lex -> MYSQL
fun -> mysql
以及一些默认的规则
HepPlanner