如何才能实现分布式 join?
有三种方式:
- 将数据全部抽取到内存中,进行内存计算。
- 将数据全部抽取到一个数据源中,直接进行查询。
- 内存和存储并用。
对于分析型的 SQL 而言,不需要考虑事务和性能的话,可以采用数据挪动的方式来实现。
如下图所示,列出了可能的实现方式。
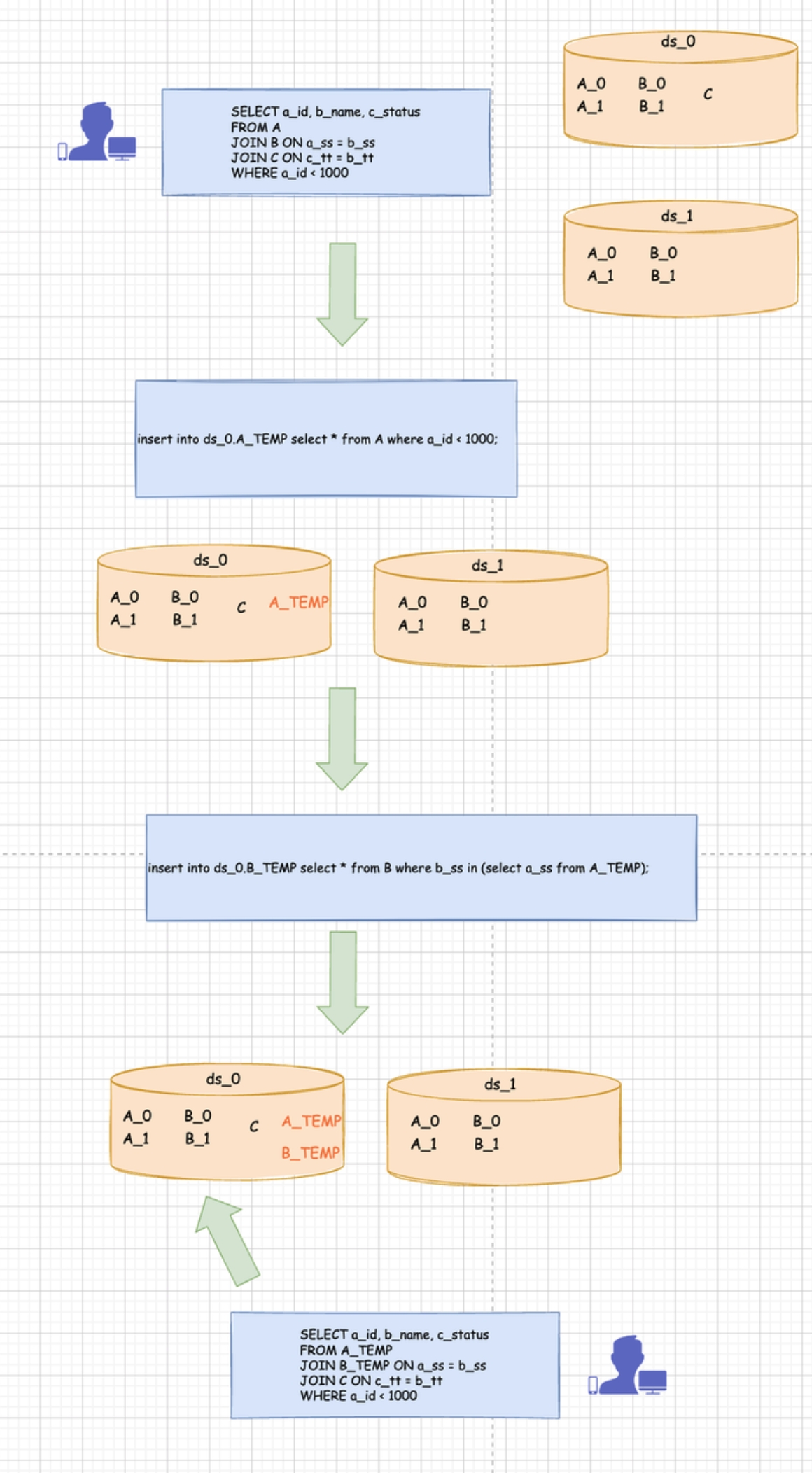
该方案的具体实现需要考虑 2 点。
- 语义分析 (考虑通过 calcite 或者自行解析提取条件)
- 获取表之间的依赖关系,例如 A left join B on condition,那么 B 依赖 A, 可以先将 A 抽取出来,再依据 A 来抽取 B
- 增加条件到表中
- 支持数据迁移(需要支持数据迁移的管理)