分布式 join 调研
Citus Data
Citus Data 是一个开源的分布式数据库管理系统,它是基于 PostgreSQL 架构之上,能够允许数据库在多个服务器之间进行分布式运算,以便应对大型数据处理和高流量负载的需求。利用 Citus Data 可以为 PostgreSQL 提供横向扩展的能力,使其可以更好地应对应用中的大量数据请求,具有较高的性能和可扩展性。Citus Data 的特点还包括良好的可用性、容错性、可管理性和可扩展性。Citrus Data 可以作为云端数据库的解决方案提供,同时也适用于在本地运行的企业数据库和分析场景中。
分布式 join 支持方式(数据复制)
单表 join 分表
下图介绍了 单表和 sharding 表 join 时 citus 的处理方式
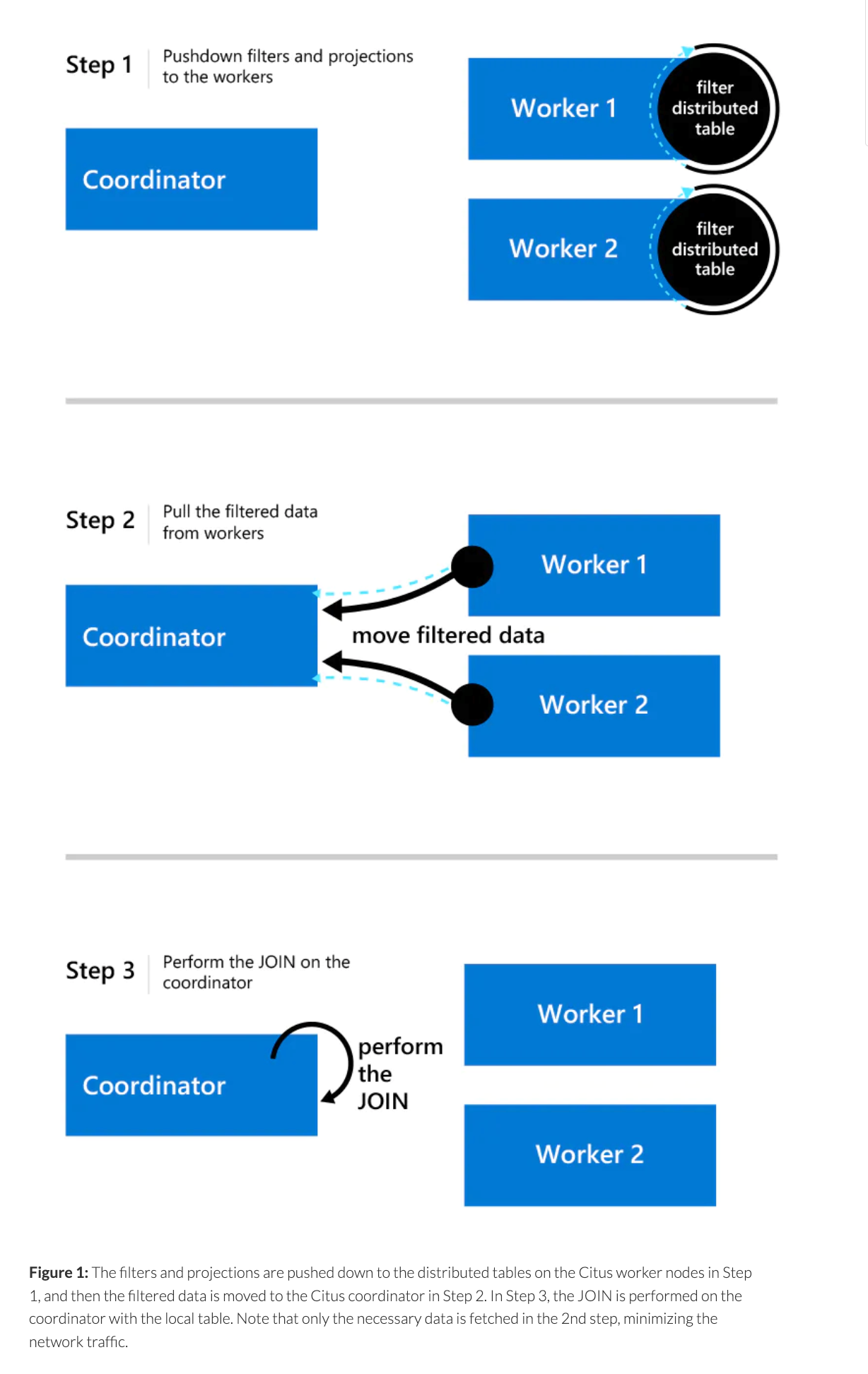
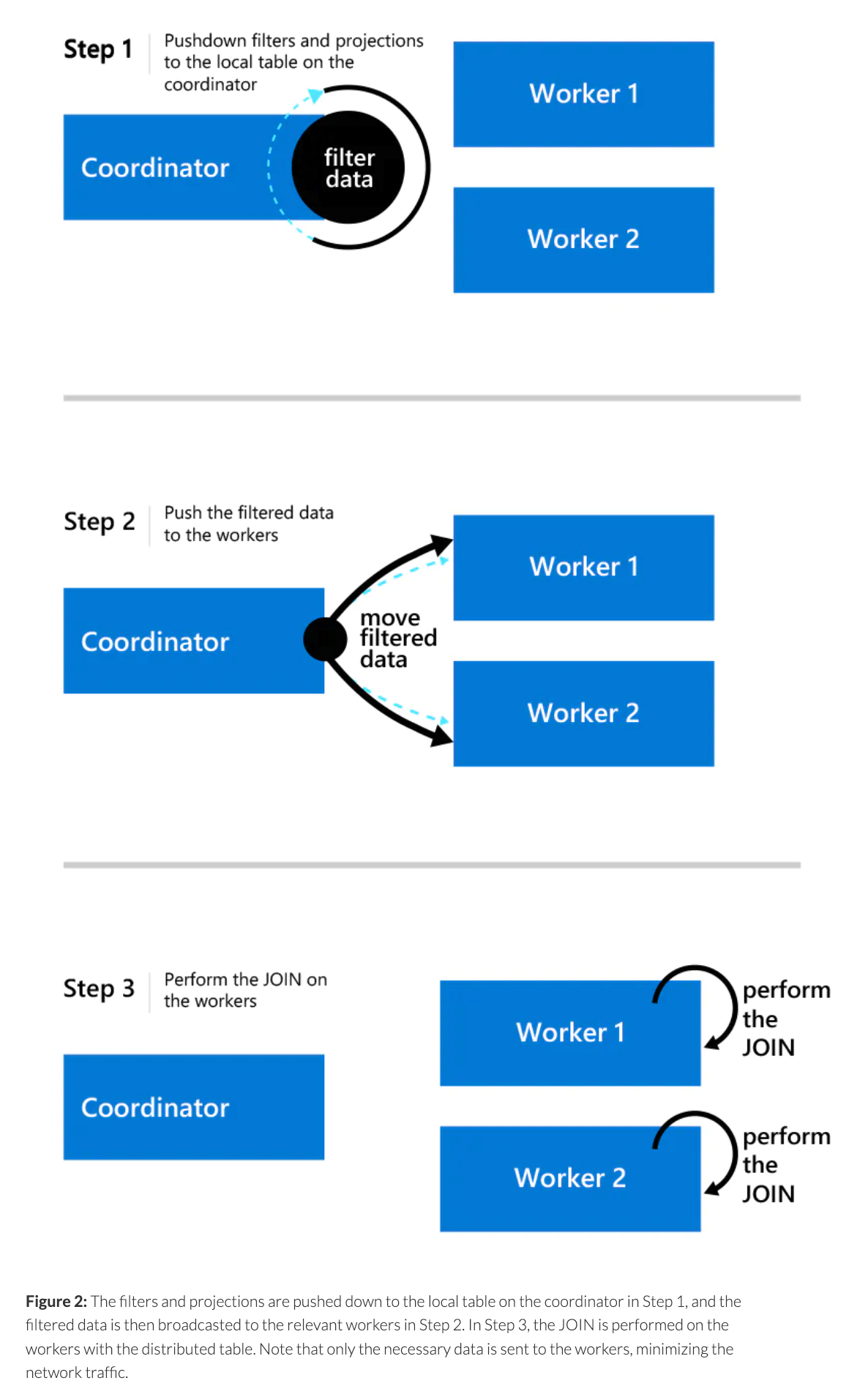
它两种方式来对 local 表和 distributed 表进行关联查询
- 将 distributed 表的数据从 workers 节点移动到协调器
- 将 local 表数据从协调器移动到 workers 节点
两种方式的选择有多种模式可以配置,例如自动模式: 因为一般来说 distributed 表的数据量比较大,所以只有当满足以下条件时才会将数据从 distributed 移动到 local 中
- 分布式表包含唯一键,如主键。
- 唯一键包含一个常量等式过滤器,可以直接或通过传递性实现。
具体模式如下:
- Auto (default): Distributed table will be moved to coordinator if the distributed table contains a constant equality filter on a unique column, which ensures less data movement from workers to the coordinator. If not, then the local table will be moved from coordinator to workers.
- Prefer-local: The filtered data of local table will be moved to the workers from the coordinator, then the JOIN will be executed on the workers.
- Prefer-distributed: The filtered data of the distributed table will be moved to the coordinator from the workers, then the JOIN will be executed on the coordinator.
- Never: Citus will give an error for local and distributed table JOINs, same as before Citus 10.
分表 join 分表

这里展示的是表的分片数量相同,并且关联条件是分片键的场景,类似于 binding table

该图展示了 citus 的 join 方式,有本地 join,refrence table join (就是广播表),还有 repartition joins,里面提到会使用数据混洗的方式,性能不高。另外这个方式需要开关打开。
根据作者对于 repartition joins https://github.com/citusdata/citus/issues/2321 的回复来看,目前该功能只能用于某些场景并且不建议默认打开使用。
Vitess
vitess 是可扩展的兼容 mysql 的云原生数据库。
分布式 join 支持方式(内存计算 + 数据复制)
没有找到官方明确的说法,但是从一些公开的演讲中发现了一些信息。 它实现分布式 join 的方式也是两种,一种是在内存中计算,另外一种就是数据复制,不过它的复制是通过 MySQL binlog。
https://www.infoq.com/presentations/vitess/ https://vitess.io/docs/16.0/reference/vreplication/vreplication/

Presto
Presto 是一个分布式 SQL 查询引擎,可以在云计算和大数据领域广泛应用。Presto 主要用于处理大数据查询和分析,它支持从多个数据源中进行高速查询,包括 Hadoop,MySQL,Cassandra,PostgreSQL 等。 Presto 的设计目的是为了在处理大量数据时提供快速的查询和分析功能。Presto 支持 SQL 查询和复杂的分析,可以处理 PB 级别的数据,并且可以在数秒内返回查询结果。Presto 的一个优点是它可以与多个数据存储系统集成,而不需要将数据迁移到一个中心位置,从而降低数据分析的成本和复杂性。它主要处理 OLAP 场景。
有点儿像 calcite。
分布式 join 支持方式(内存计算 + 数据复制)

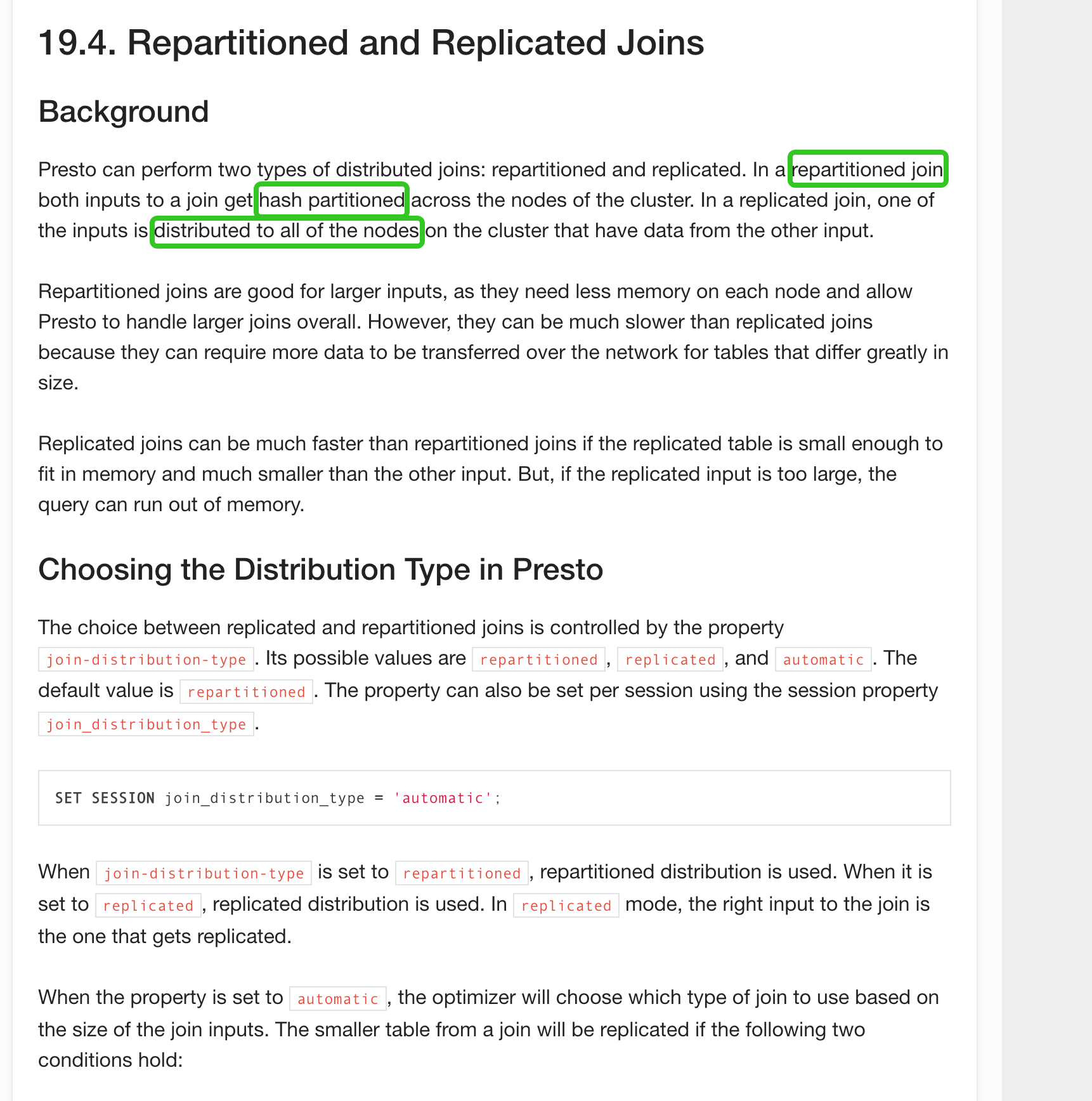
从上述文档可以看到 presto 是基于代价的查询优化器。一般也是两种方式实现分布式 join
- Partitioned: each node participating in the query builds a hash table from only a fraction of the data
- Broadcast: each node participating in the query builds a hash table from all of the data (data is replicated to each node)
partitioned 方式是输入数据的部分生成 hash 表然后去各个节点上迭代。
broadcast 的方式则是基于全部数据生成 hash 表然后 join。
参考文档
https://docs.citusdata.com/en/stable/articles/outer_joins.html
https://prestodb.io/docs/current/optimizer/cost-based-optimizations.html
https://docs.treasuredata.com/display/public/PD/About+Presto+Distributed+Query+Engine