Target
- 说清楚 calcite 是什么,能做什么
- 画出 calcite 的大体架构
- 明白 calcite 是如何跟 SS 整合的
- 未来 SS 还可以在哪些方面进一步利用 calcite
- calcite 优化逻辑源码级理解
- 在 calcite 上提交 pr
Process
calcite 是什么,能做什么
calcite 是动态数据的管理框架。我理解,就是数据库的计算层,去除掉了存储的部分。 calcite 可以接入任何形式的数据,只需要我们将数据注册成表的形式,那么就可以使用 SQL 来对它进行查询。
calcite 的大体架构
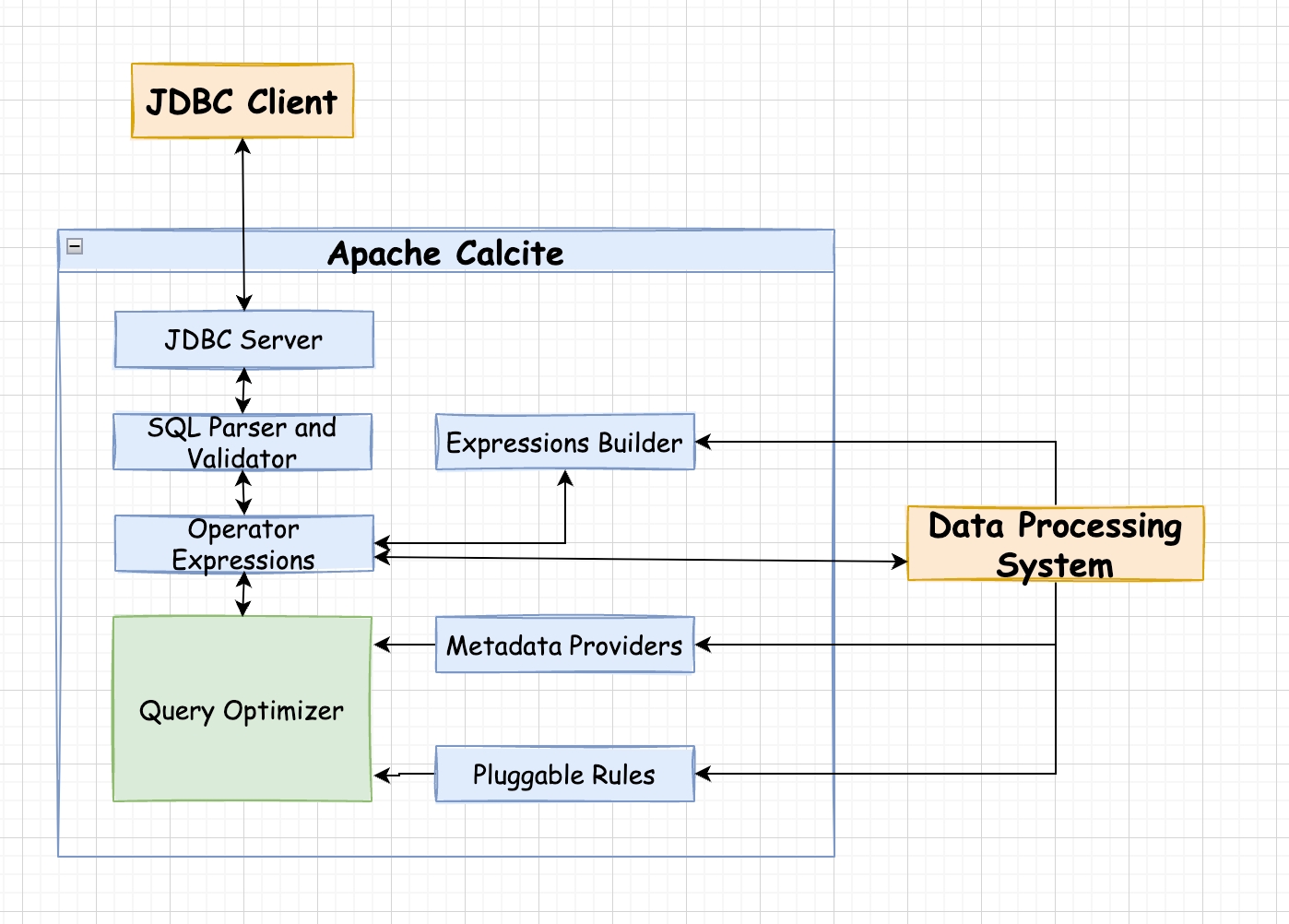
calcite 如何跟 SS 整合
ShardingSphere 可以支持分库分表,所以也自然会有跨实例查询的 SQL。 例如跨实例的 join。这些 SQL 是没办法直接下推到数据库去执行的,因此利用 calcite 来实现复杂子查询或者是跨实例 join。 我们可以从一个跨实例 join 的 select debug 来查看整合 calcite 的方式。 1. 执行查询前,会先构造 OptimizerContext,里面包含一些数据库的配置,例如 caseSensitive -> false conformance -> MYSQL_5 timeZone -> UTC lex -> MYSQL fun -> mysql 以及一些默认的规则 HepPlanner
- 注册 schema 将表转化为 translatable table
- 创建 CalciteCatalogReader 对象(参数: rootSchema, schemaName, RelDataTypeFactory, CalciteConnectionConfig)
- 创建 SqlValidator
- 创建 SqlToRelConverter
- 拿到之前的 RelOptPlanner (HepPlanner)
- 将 shardingsphere 的 sqlstatement 转化成 SqlNode
- 利用 SqlToRelConverter 将 sqlNode 转化为 RelNode
- 然后分别进行RBO 和 CBO 优化
- 将优化结果与 dataContext 绑定
- 在 FilterableTableScanExecutor 执行下推逻辑,下推到各个逻辑库上执行。
- 将结果集封装到 ResultSet 中
- 同普通查询后续流程一致
如何规划执行?默认每个表下推一次吗? 从目前代码的 TranslatableTableScanExecutor 来看,确实是单表的下推。
未来 SS 还可以在哪些方面进一步利用 calcite
- 内存的优化,目前全部都是抽取到内存中,大数据会 OOM
- 自定义算子的实现
- 利用数据的收集做代价优化
calcite 优化逻辑源码级理解
calcite 解决编译报错问题
checkout 到最近 release 的tag
注释掉 build.gradle.kts 中的 releaseArtifacts