文档信息提取
https://developer.aliyun.com/article/783392 本文首先介绍了 MySQL 的 join 实现,包括以下方式
- Nested-Loop Join (NL Join)
- Batched Key Access Join (BKA Join)
- Block Nested-Loop Join(版本 < 8.0.20)
- Hash Join (版本 >= 8.0.18)
polardb-x 支持多种 join 方式,包括 Lookup Join、Nested-Loop Join、Hash Join、Sort-Merge Join 等,本文主要讲的是 Lookup Join
lookup join
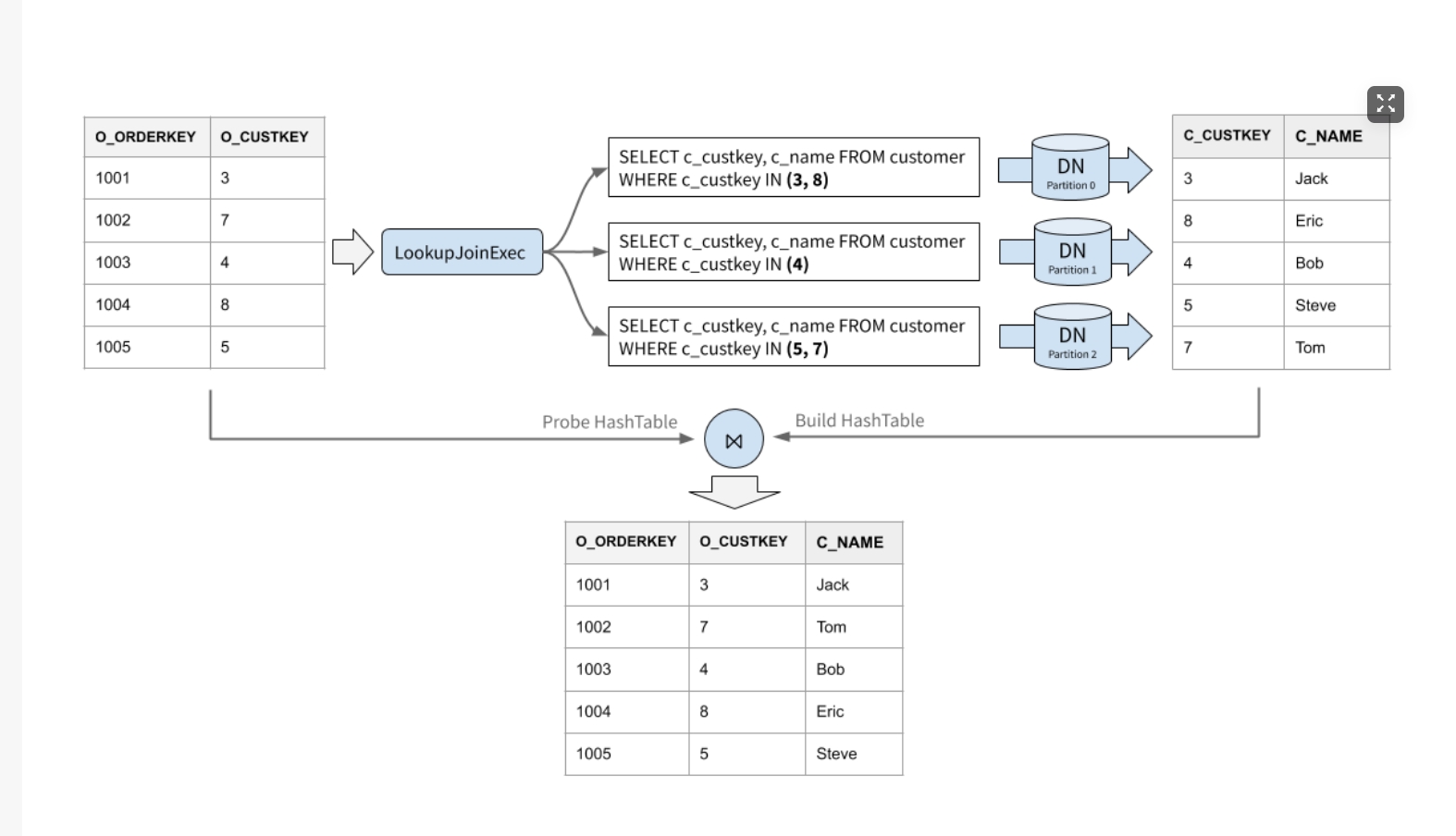
Lookup Join 的执行过程如下(非索引回表情形):
- 从驱动侧拉取一批数据。通常情况下数据量不会很多,如果数据较多,那么每个批的大小受到 lookup 端的分片数量以及是否可以进行分片裁剪限制。批大小的选择会直接影响查询性能,如果批特别小会导致 RPC 次数太高,批太大则会导致内存中暂存的数据量膨胀,高并发情况下可能导致 OOM。默认情况下我们尽可能让每个分片平均查询 50 个值、最多不超过 300 个值。
- 计算 batch 内每行数据所在分片,由于 lookup 侧是一个分区表,驱动表的每行数据要 lookup 的数据位于不同的分区中。只有包含数据的分片才需要参与 Join,如果没有任何值被路由到某个分片上,那么这个分片也无需被 Lookup。
- 并发请求所有需要 lookup 的分片,并将查到的数据行以 Join Key 为 Key 构建成哈希表,缓存在内存中。
- 类似于 Hash Join,利用哈希表为驱动侧的每行找到与其 Join 的行,取决于 Join 类型,可能 Join 出 0 行、1 行或多行。
|
|
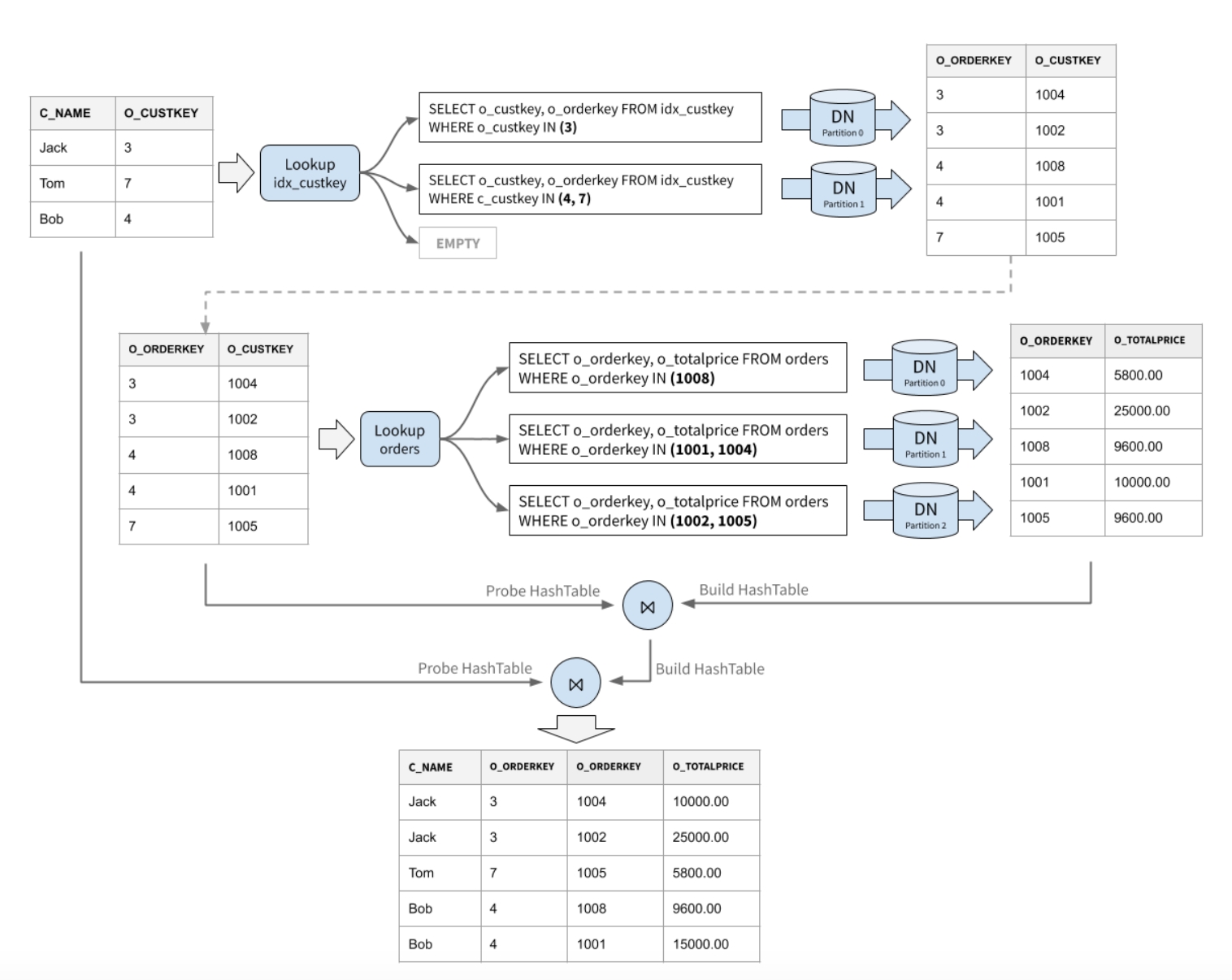
依赖全局索引的 Join 则更为复杂一些,回忆下 MySQL 的 BKA Join,需要进行两次 lookup:
- 第一次用 Join key 查询全局索引表(用于 Join)
- 第二次用全局索引表中的主键查询主表(用于索引回表)
- 将回表结果以 PK 为 key 构建哈希表,与2中的查询结果 Join,得到完整的 Join 右侧数据
- 将完整的 Join 右侧数据以 Join Key 为 key 构建哈希表,与 1 的数据 Join,得到最终 Join 结果
|
|
文档信息提取
https://help.aliyun.com/document_detail/316601.html
Nested-Loop Join (NLJoin)
一般是含有不等式条件场景下会使用 流程如下:
- 拉取内表(右表,通常是数据量较小的一边)的全部数据,缓存到内存中。
- 遍历外表数据,对于外表的每行:
- 对于每一条缓存在内存中的内表数据。
- 构造结果行,并检查是否满足JOIN条件,如果满足条件则输出。
支持通过 hint 来定义顺序
Hash Join
Hash Join是等值JOIN最常用的算法之一。它的原理如下所示:
- 拉取内表(右表,通常是数据量较小的一边)的全部数据,写进内存中的哈希表。
- 遍历外表数据,对于外表的每行:
- 根据等值条件JOIN Key查询哈希表,取出0-N匹配的行(JOIN Key相同)。
- 构造结果行,并检查是否满足JOIN条件,如果满足条件则输出。
当索引无法满足,不能使用 lookup join 的时候,可以使用 hash join
Sort-Merge Join
Sort-Merge Join是另一种等值JOIN算法,它依赖左右两边输入的顺序,必须按JOIN Key排序。它的原理如下:
- 开始Sort-Merge Join之前,输入端必须排序(借助MergeSort或MemSort)。
- 比较当前左右表输入的行,并按以下方式操作,不断消费左右两边的输入:
- 如果左表的JOIN Key较小,则消费左表的下一条数据。
- 如果右表的JOIN Key较小,则消费右表的下一条数据。
- 如果左右表JOIN Key相等,说明获得了1条或多条匹配,检查是否满足JOIN条件并输出。
关于 Join 顺序以及各种 join 的使用场景

文档信息提取
https://zhuanlan.zhihu.com/p/379967662
面对 OLTP 场景,可以使用大表和小表进行 join ,使用前文提到的 Lookup Join 算法 但是对于 OLAP 的场景,我们可能就需要将数据从内存拉出来进行计算。
等值 JOIN 那么一般就是 hash-join 和 sort-merge join 两种,Hash join 根据是否支持大数据量,又分为 内存 Hash-join 和 落盘版的 Hash-join
内存版 Hash join 的实现
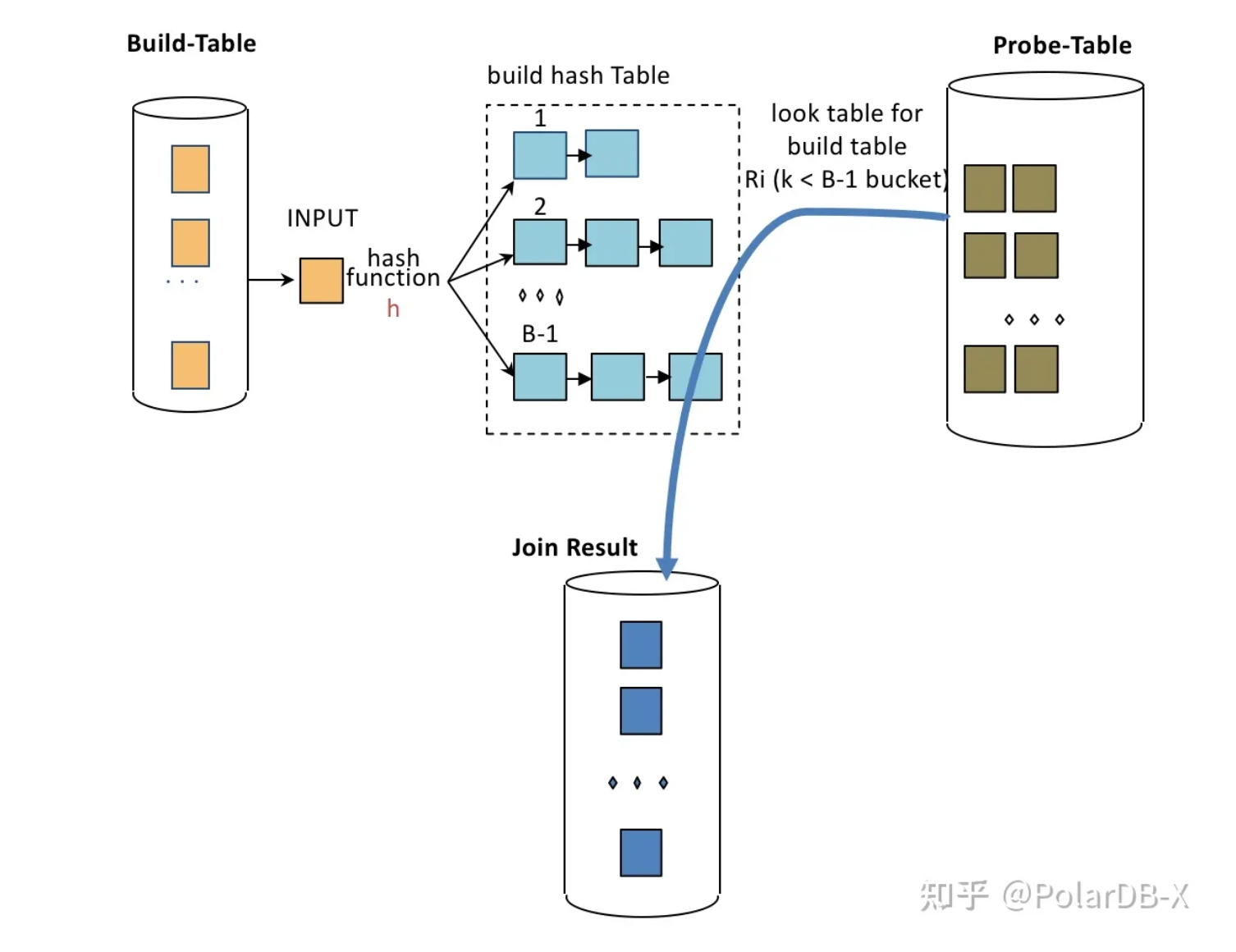
根据统计信息选取较小的表根据 join 条件对给定的列 build hash table,然后流式遍历,去 hash table 里面找 key,如果一致,那么就拿出一整行,然后直接向下游输出,这个过程又叫 probe table
//build Table
for row in t1:
hashValue = hash_func(row)
put (hashValue, row) into hash-table;
//probe Table
for row in t2:
hashValue = hash_func(row)
t1_row = lookup from hash-table
if (t1_row != null) {
join(t1_row, row)
}
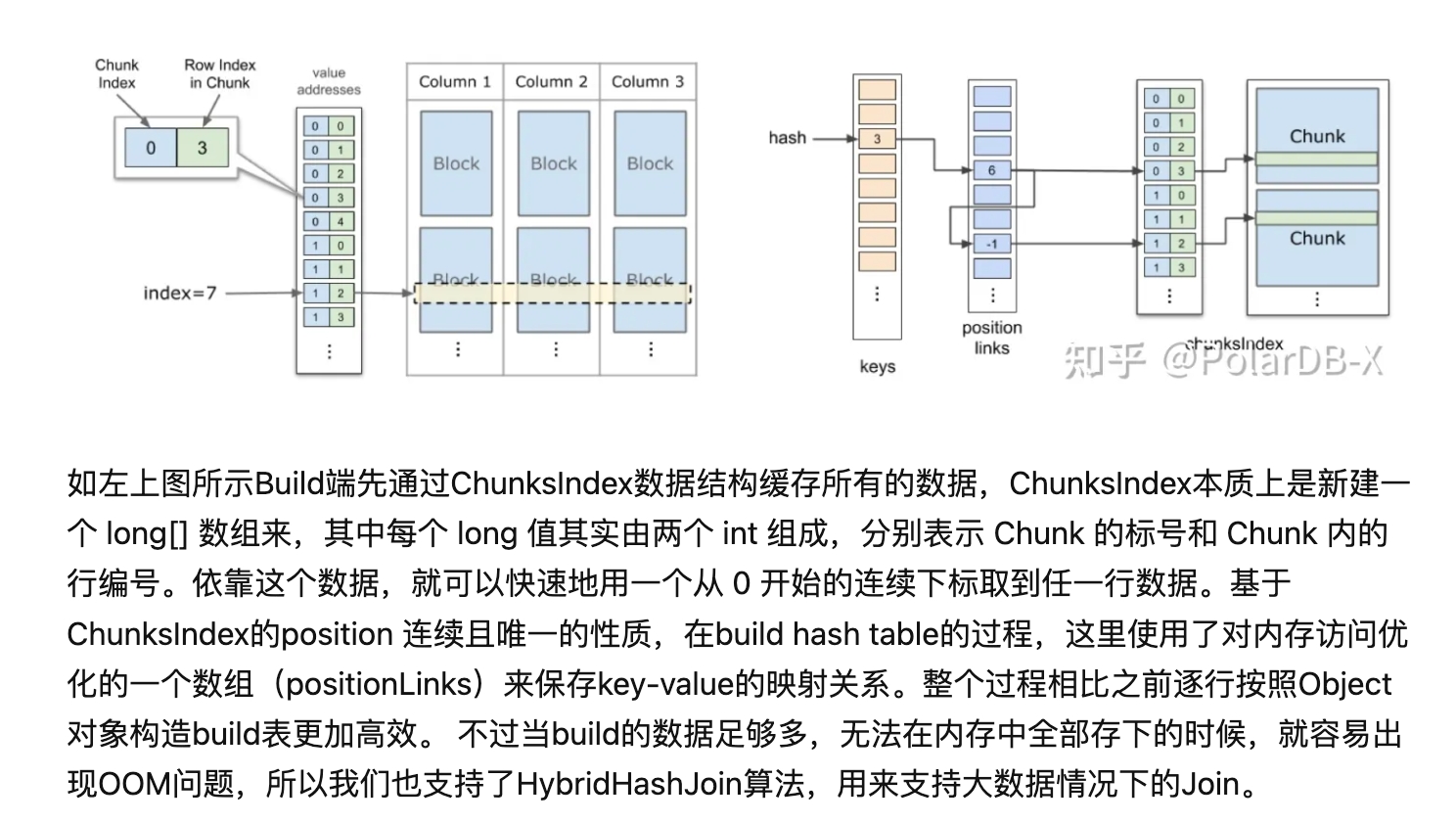
polardb-x 与一般的 hash join 最大的不同,是采用了内存友好的 vector 重新实现了哈希表,对 CPU CACHE 更友好,可以提高 JOIN 性能。
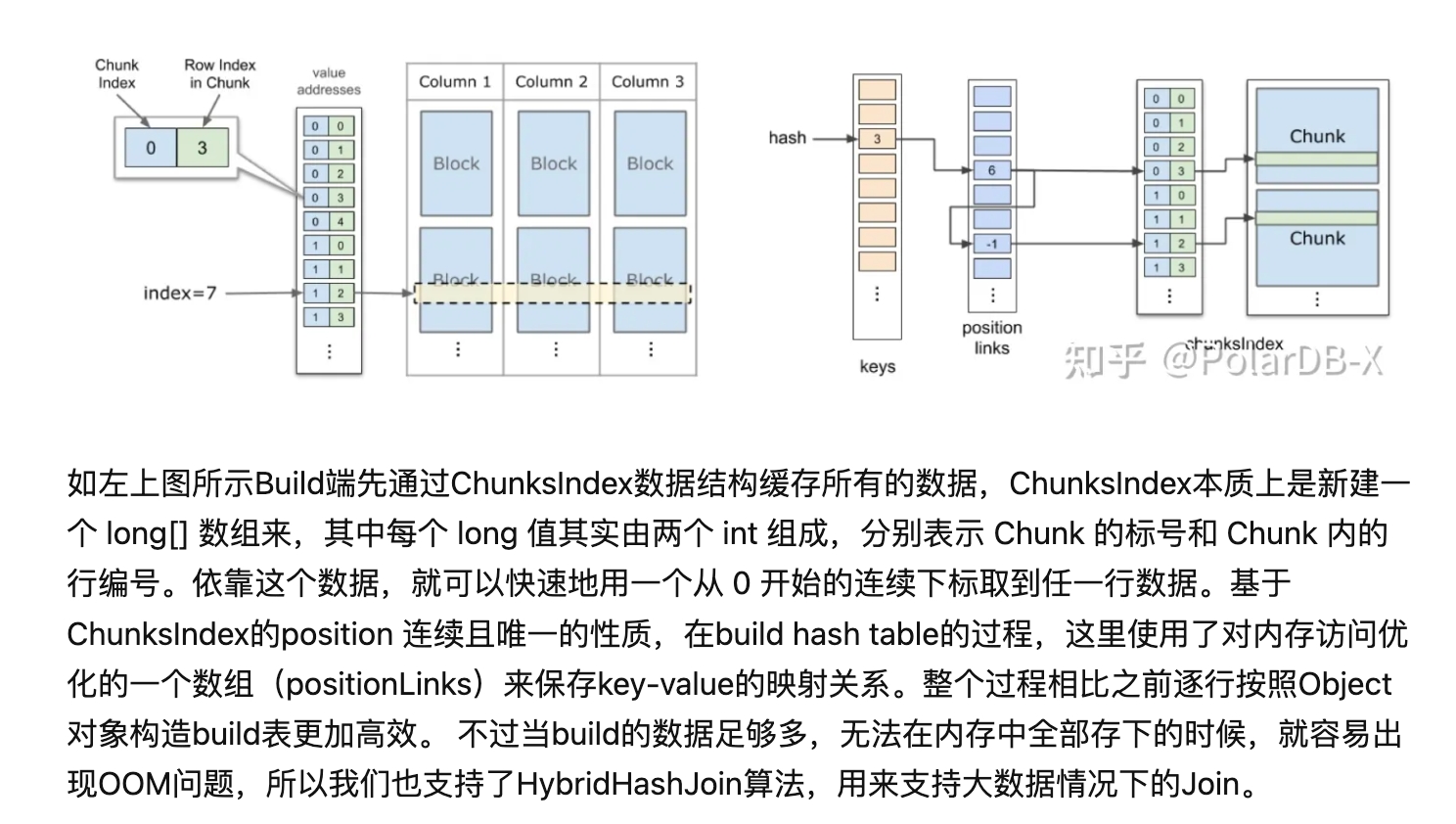 具体实现没太明白。。。大概是搞了一些缓存索引结构?
具体实现没太明白。。。大概是搞了一些缓存索引结构?
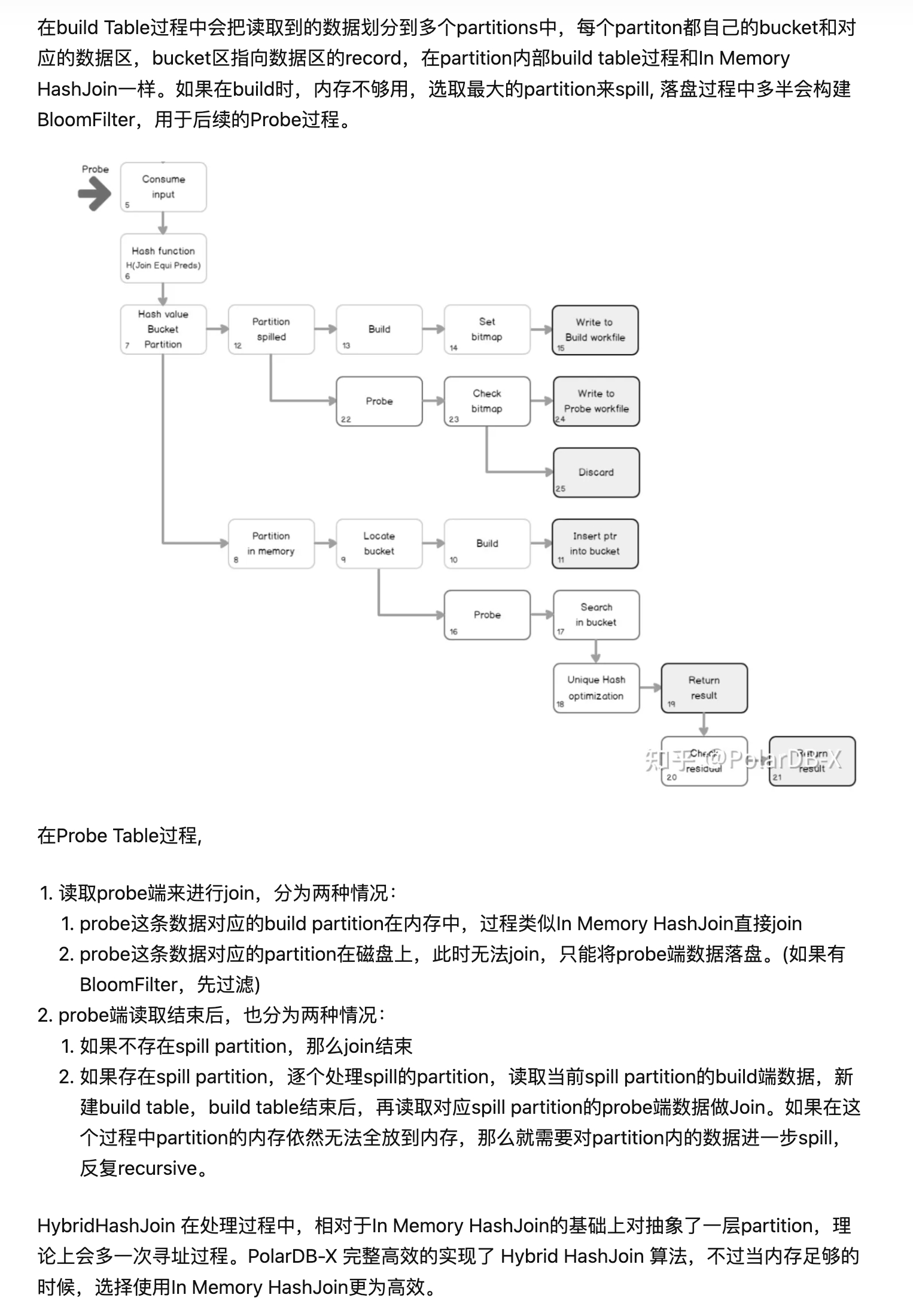
如果数据量太大,无法全部放到内存中的时候,那么就需要使用 HybridHashJoin 算法。
HybirdHashJoin
Hybird hash join 从我的角度理解,就是将原表按照关联的键做 partition,然后分别在每个分区做 hash join.
SortMergeJoin
sort t1, sort t2
R1 = t1.next()
R2 = t2.next()
while (R1 != null && R2 != null) {
if R1 joins with R2
output (R1, R2)
else if R1 < R2
R1 = t1.next()
else
R2 = t2.next()
}
这种场景一般外排序会比较消耗 IO,一般 hash join.不过某些极端场景下, hash join 分桶之后,数据量还是超限,那么这种场景可能 sort merge join 就比较优势了。
Shuffle join
TODO