新增 SS 默认系统库,初步支持全局静态元数据(编码、事务隔离级别)管理
设计元数据调度收集功能,支持 ShardingSphere 动态元数据管理(数据分布等信息)
当 前 ss 缺乏自己的元数据信息,例如分片的数据分布、编码等等。
之前为了解决各个客户端连接报错的问题,设计了各个数据库方言的模拟库。
只有用户表会从真实数据库获取,其他表都是通过 yaml 文件来模拟存储到 zk 的。
Mysql 将相关参数放在 variables_info 并将相关值设置在全局或 session 级别对应的表中
1
2
3
4
5
6
7
8
9
10
11
mysql > show tables like '%variables%' ;
+ --------------------------------------------+
| Tables_in_performance_schema ( % variables % ) |
+ --------------------------------------------+
| global_variables |
| persisted_variables |
| session_variables |
| user_variables_by_thread |
| variables_by_thread |
| variables_info |
+ --------------------------------------------+
查询隔离级别
1
2
3
4
5
6
7
8
9
10
11
mysql > SELECT VI . VARIABLE_NAME , GV . VARIABLE_VALUE , VI . MIN_VALUE , VI . MAX_VALUE
FROM performance_schema . variables_info AS VI
INNER JOIN performance_schema . global_variables AS GV USING ( VARIABLE_NAME )
where variable_name = 'transaction_isolation'
ORDER BY VARIABLE_NAME ;
+ -----------------------+-----------------+-----------+-----------+
| VARIABLE_NAME | VARIABLE_VALUE | MIN_VALUE | MAX_VALUE |
+ -----------------------+-----------------+-----------+-----------+
| transaction_isolation | REPEATABLE - READ | 0 | 0 |
+ -----------------------+-----------------+-----------+-----------+
1 row in set ( 0 . 01 sec )
pg_settings 表
1
2
3
4
5
postgres =# select * from pg_settings where name = 'default_transaction_isolation' ;
name | setting | unit | category | short_desc | extra_desc | context | vartype | source | min_val | max_val | enumvals | boot_val | reset_val | sourcefile | sourceline | pending_restart
-------------------------------+----------------+------+-------------------------------------------------+---------------------------------------------------------------+------------+---------+---------+---------+---------+---------+----------------------------------------------------------------------+----------------+----------------+------------+------------+-----------------
default_transaction_isolation | read committed | | Client Connection Defaults / Statement Behavior | Sets the transaction isolation level of each new transaction . | | user | enum | default | | | { serializable , "repeatable read" , "read committed" , "read uncommitted" } | read committed | read committed | | | f
( 1 row )
Polardb-x 的元数据库
Polardb-x 中维护了自己的元数据库用于内部流程的使用
它的元数据中几乎维护了所有需要的信息,例如 tables,columns,lock,ddl_job, schedule job 等。
另外在内存中也维护了一份元数据信息,主要是表、列。内存中元数据来源于存储在 mysql 中的元数据,每次 ddl 执行后,都会生成刷新对应表的任务,通过任务触发 cn 从 mysql 中查询并缓存。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
mysql > show tables ;
+ ---------------------------------------+
| Tables_in_polardbx_meta_db_polardbx |
+ ---------------------------------------+
| __test_sequence |
| __test_sequence_opt |
| audit_log |
| backfill_objects |
| baseline_info |
| binlog_polarx_command |
| character_sets |
| checker_reports |
| collation_character_set_applicability |
| collations |
| column_metas |
| column_statistics |
| columns |
| complex_task_outline |
| concurrency_control_rule |
| concurrency_control_trigger |
| config_listener |
| db_group_info |
| db_info |
| db_priv |
| ddl_engine |
| ddl_engine_archive |
| ddl_engine_task |
| ddl_engine_task_archive |
| ddl_plan |
| default_role_state |
| engines |
| feature_usage_statistics |
| file_storage_files_meta |
| file_storage_info |
| files |
| fired_scheduled_jobs |
| global_variables |
| group_detail_info |
| indexes |
| inst_config |
| inst_lock |
| key_column_usage |
| locality_info |
| node_info |
| partition_group |
| partition_group_delta |
| partitions |
| plan_info |
| quarantine_config |
| read_write_lock |
| recycle_bin |
| referential_constraints |
| role_priv |
| scaleout_backfill_objects |
| scaleout_checker_reports |
| scaleout_outline |
| scheduled_jobs |
| schema_change |
| schemata |
| sequence |
| sequence_opt |
| server_info |
| session_variables |
| storage_info |
| table_constraints |
| table_group |
| table_local_partitions |
| table_partitions |
| table_partitions_delta |
| table_priv |
| table_statistics |
| tablegroup_outline |
| tables |
| tables_ext |
| user_login_error_limit |
| user_priv |
| variable_config |
| views |
+ ---------------------------------------+
74 rows in set ( 0 . 02 sec )
简述:整个 ddl 过程中涉及了 ddl-job 任务相关表的使用(ddl_engine 、ddl_engine_task ),表相关元数据的使用(tables、tables_ext、columns)以及锁 (read_write_lock)等。
以 DDL 语句为例,我们看一下 polardb-x 是怎么使用 metadata 的
1
CREATE TABLE t1 ( id bigint not null auto_increment , name varchar ( 30 ), primary key ( id )) dbpartition by hash ( id );
SQL语句进入PolarDB-X的CN后,将经历协议层、优化器、执行器的完整处理流程。首先经过解析、鉴权、校验,被解析为关系代数树后,在优化器中经历RBO和CBO生成执行计划,最终在DN上执行完成。
由于 DDL 涉及元数据的变更,所以可能会造成系统状态的不一致。所以 polardb-x 通过 ddl job 配合 metadataDb 以及 双版本元数据 + MDL锁来解决这个问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
@Override
public Cursor handle ( RelNode logicalPlan , ExecutionContext executionContext ) {
BaseDdlOperation logicalDdlPlan = ( BaseDdlOperation ) logicalPlan ;
initDdlContext ( logicalDdlPlan , executionContext );
// Validate the plan first and then return immediately if needed.
boolean returnImmediately = validatePlan ( logicalDdlPlan , executionContext );
boolean isNewPartDb = DbInfoManager . getInstance (). isNewPartitionDb ( logicalDdlPlan . getSchemaName ());
if ( isNewPartDb ) {
setPartitionDbIndexAndPhyTable ( logicalDdlPlan );
} else {
setDbIndexAndPhyTable ( logicalDdlPlan );
}
// Build a specific DDL job by subclass.
DdlJob ddlJob = returnImmediately ?
new TransientDdlJob ():
buildDdlJob ( logicalDdlPlan , executionContext );
// Validate the DDL job before request.
validateJob ( logicalDdlPlan , ddlJob , executionContext );
// Handle the client DDL request on the worker side.
handleDdlRequest ( ddlJob , executionContext );
if ( executionContext . getDdlContext (). isSubJob ()){
return buildSubJobResultCursor ( ddlJob , executionContext );
}
return buildResultCursor ( logicalDdlPlan , executionContext );
}
将 sql 转化为执行计划后,就会创建 ddl job, ddl job 中包含了新增表信息到元数据库、创建物理表、同步元数据信息等任务。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
@Override
protected ExecutableDdlJob doCreate () {
CreateTableValidateTask validateTask =
new CreateTableValidateTask ( schemaName , logicalTableName , physicalPlanData . getTablesExtRecord ());
CreateTableAddTablesExtMetaTask addExtMetaTask =
new CreateTableAddTablesExtMetaTask ( schemaName , logicalTableName , physicalPlanData . isTemporary (),
physicalPlanData . getTablesExtRecord (), autoPartition );
CreateTablePhyDdlTask phyDdlTask = new CreateTablePhyDdlTask ( schemaName , logicalTableName , physicalPlanData );
CdcDdlMarkTask cdcDdlMarkTask = new CdcDdlMarkTask ( schemaName , physicalPlanData );
CreateTableAddTablesMetaTask addTableMetaTask =
new CreateTableAddTablesMetaTask ( schemaName , logicalTableName , physicalPlanData . getDefaultDbIndex (),
physicalPlanData . getDefaultPhyTableName (), physicalPlanData . getSequence (),
physicalPlanData . getTablesExtRecord (), physicalPlanData . isPartitioned (),
physicalPlanData . isIfNotExists (), physicalPlanData . getKind (), hasTimestampColumnDefault ,
binaryColumnDefaultValues );
LocalityDesc locality = physicalPlanData . getLocalityDesc ();
StoreTableLocalityTask storeLocalityTask = locality == null ?
null :
new StoreTableLocalityTask ( schemaName , logicalTableName , locality . toString (), false );
CreateTableShowTableMetaTask showTableMetaTask = new CreateTableShowTableMetaTask ( schemaName , logicalTableName );
TableSyncTask tableSyncTask = new TableSyncTask ( schemaName , logicalTableName );
ExecutableDdlJob4CreateTable result = new ExecutableDdlJob4CreateTable ();
...
result . setCreateTableValidateTask ( validateTask );
result . setCreateTableAddTablesExtMetaTask ( addExtMetaTask );
result . setCreateTablePhyDdlTask ( phyDdlTask );
result . setCreateTableAddTablesMetaTask ( addTableMetaTask );
result . setCdcDdlMarkTask ( cdcDdlMarkTask );
result . setCreateTableShowTableMetaTask ( showTableMetaTask );
result . setTableSyncTask ( tableSyncTask );
return result ;
创建 ddl job 之后,就会下发执行任务,storeJob 会将相关 job 写入ddl_engine_task,ddl_engine 表中。
notifyLeader 会通知相关 cn 节点执行 ddl job。ddl job 会更新元数据库中的 tables columns 等表,如果有多个 cn 节点,这里会触发节点间同步,收到同步信息的节点会从元数据中获取相关信息,并更新 cn 内缓存的元数据信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public void execute () {
ddlContext . setResources ( ddlJob . getExcludeResources ());
// Create a new job and put it in the queue.
ddlJobManager . storeJob ( ddlJob , ddlContext );
// Request the leader to perform the job.
DdlRequest ddlRequest = notifyLeader ( ddlContext . getSchemaName (), Lists . newArrayList ( ddlContext . getJobId ()));
// Wait for response from the leader, then respond to the client.
if ( ddlContext . isAsyncMode ()) {
return ;
}
respond ( ddlRequest , ddlJobManager , executionContext , true );
}
关于元数据 GMS 三副本节点
polarDb-x 的元数据存储于内置的 GMS 三副本节点中,提供了全局时间戳来提供外部一致性读,具体可以参考:PolarDB-X 全局时间戳服务的设计
PolarDB-X 一致性共识协议 (X-Paxos)-阿里云开发者社区
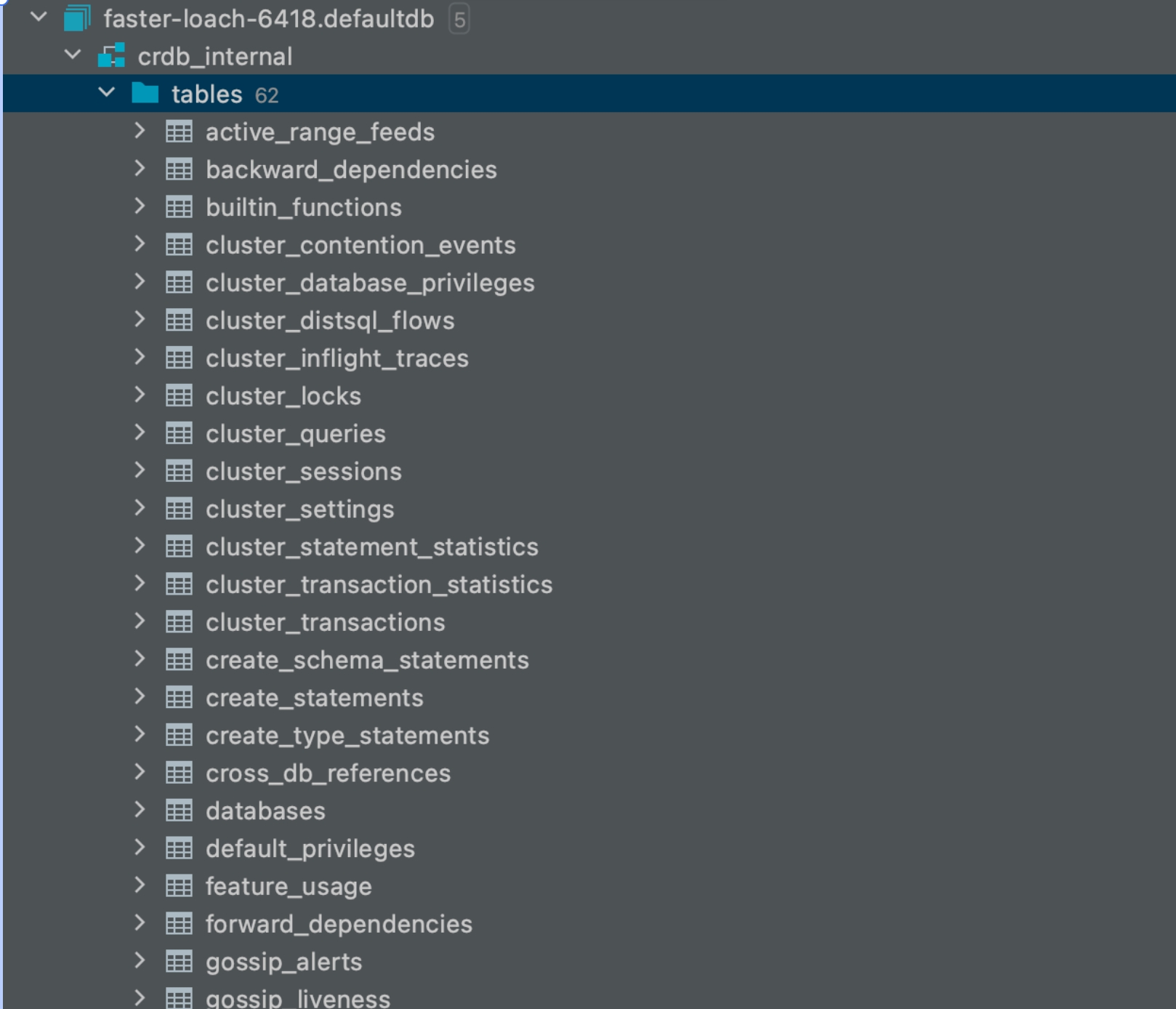
Cockroach db 的内置元数据库
Cockroach 的底层存储结构如下:
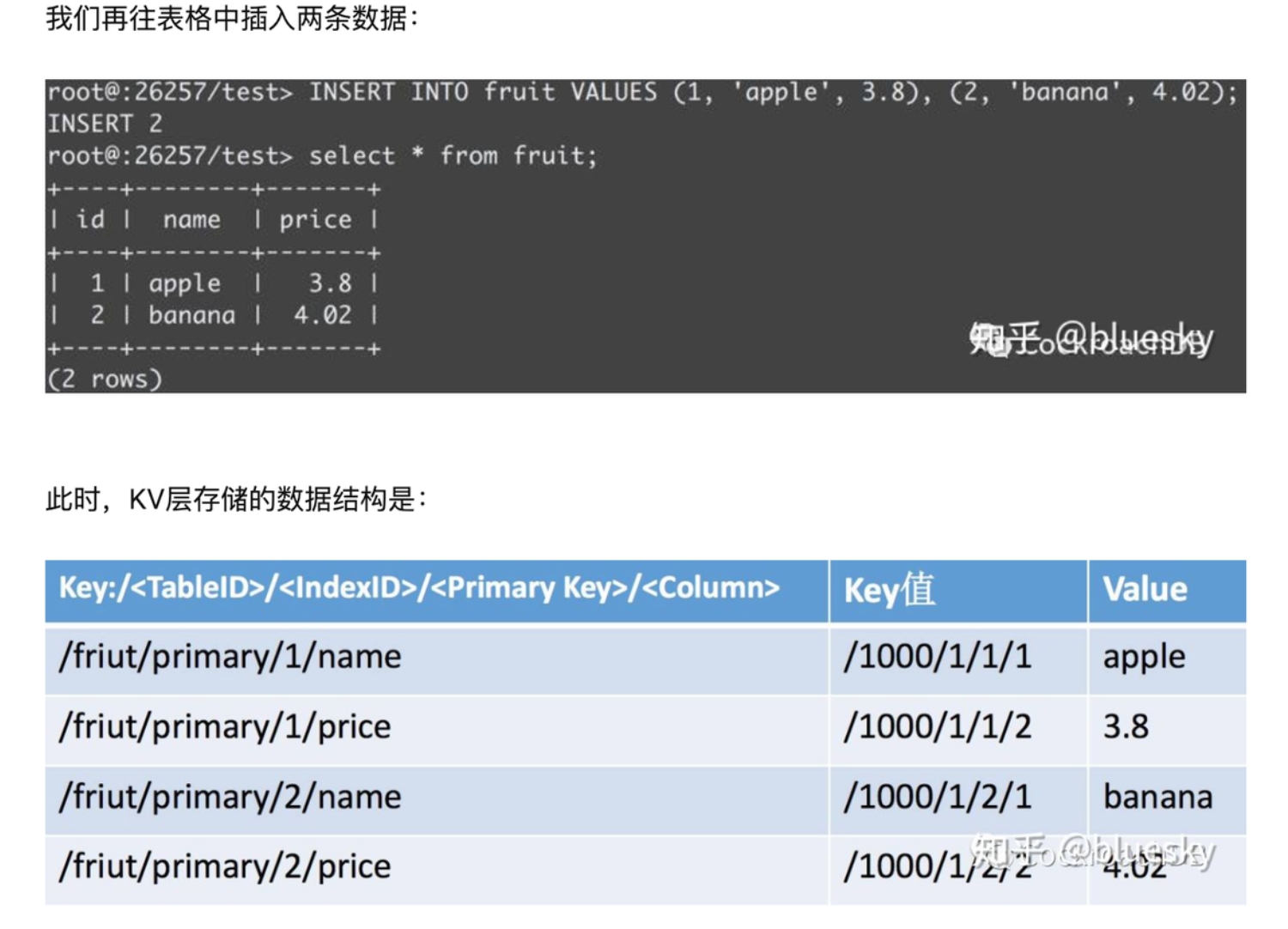
以 分片表数据量统计表 为例
create table sharding_table_statistics (
id int,
logic_database_name varchar(100),
logic_table_name varchar(100),
actual_database_name varchar(100),
actual_table_name varchar(100),
row_count BIGINT,
size BIGINT
)
对应 zk 存储结构
红色为修改,黄色为新增,蓝色为 PG 特有(pg 同一个实例上的库是不共享元数据信息的,所以 pg 的 shardingsphere schema 增加在用户创建的逻辑库下,当然 postgres 库下也会模拟一个 shardingsphere schema)
初始化
通过 yaml 模拟生成表结构(同现有 information_schema 流程)
从 zk 获取 ShardingSphereData 对象
如果未获取到,根据表结构初始化 ShardingSphereData 对象
注册表结构到 calcite 方便进行查询使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public static MetaDataContexts create ( final MetaDataPersistService persistService , final ContextManagerBuilderParameter parameter ,
final InstanceContext instanceContext ) throws SQLException {
Collection < String > databaseNames = instanceContext . getInstance (). getMetaData () instanceof JDBCInstanceMetaData
? parameter . getDatabaseConfigs (). keySet ()
: persistService . getDatabaseMetaDataService (). loadAllDatabaseNames ();
Map < String , DatabaseConfiguration > effectiveDatabaseConfigs = createEffectiveDatabaseConfigurations ( databaseNames , parameter . getDatabaseConfigs (), persistService );
Collection < RuleConfiguration > globalRuleConfigs = persistService . getGlobalRuleService (). load ();
ConfigurationProperties props = new ConfigurationProperties ( persistService . getPropsService (). load ());
// 增加元数据库表结构的初始化
Map < String , ShardingSphereDatabase > databases = ShardingSphereDatabasesFactory . create ( effectiveDatabaseConfigs , props , instanceContext );
databases . putAll ( reloadDatabases ( databases , persistService ));
ShardingSphereRuleMetaData globalMetaData = new ShardingSphereRuleMetaData ( GlobalRulesBuilder . buildRules ( globalRuleConfigs , databases , instanceContext , props ));
ShardingSphereMetaData metaData = new ShardingSphereMetaData ( databases , globalMetaData , props );
ShardingSphereData shardingSphereData = initShardingSphereData ( persistService , metaData , instanceContext );
return new MetaDataContexts ( persistService , metaData , shardingSphereData );
}
1
2
3
4
5
6
7
private static ShardingSphereData initShardingSphereData ( final MetaDataPersistService persistService , final ShardingSphereMetaData metaData , final InstanceContext instanceContext ) {
// 先从 zk 加载,没有的话就依赖之前的表结构进行初始化
ShardingSphereData result = persistService . getShardingSphereDataPersistService (). load (). orElse ( ShardingSphereDataFactory . getInstance ( metaData ));
// 注册表结构到 calcite 方便后续查询使用
result . registerShardingSphereDataQueryEngine ( metaData , instanceContext . getEventBusContext ());
return result ;
}
初始化数据收集任务 (目前考虑采用监听 zk 的方式来触发相关任务的收集 + 定时任务收集)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
@Slf4j
public final class ShardingSphereDataContextManagerLifecycleListener implements ContextManagerLifecycleListener {
@Override
public void onInitialized ( final ModeConfiguration modeConfig , final ContextManager contextManager ) {
ShardingSphereDataJobWorker . initialize ( contextManager );
}
}
public final class ShardingSphereDataJobWorker {
private static final AtomicBoolean WORKER_INITIALIZED = new AtomicBoolean ( false );
/**
* Initialize job worker.
* @param contextManager context manager
*/
public static void initialize ( final ContextManager contextManager ) {
if ( WORKER_INITIALIZED . get ()) {
return ;
}
synchronized ( WORKER_INITIALIZED ) {
if ( WORKER_INITIALIZED . get ()) {
return ;
}
log . info ( "start worker initialization" );
// 开启定时收集线程
startScheduleThread ( contextManager );
// 监听 收集任务 zk 节点
ShardingSphereDataNodeWatcher . getInstance ();
WORKER_INITIALIZED . set ( true );
log . info ( "worker initialization done" );
}
}
private static void startScheduleThread ( final ContextManager contextManager ) {
// TODO start thread to collect data
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
public final class MetaDataContexts implements AutoCloseable {
private final MetaDataPersistService persistService ;
private final ShardingSphereMetaData metaData ;
private final ShardingSphereData shardingSphereData ;
/**
* Sharding sphere data.
*/
@Getter
public final class ShardingSphereData {
..
// key: table name value: table data
private final Map < String , ShardingSphereTableData > tableData = new LinkedHashMap <> ();
..
}
@RequiredArgsConstructor
@Getter
public class ShardingSphereTableData {
private final String name ;
private final List < ShardingSphereRowData > rows = new LinkedList <> ();
}
@RequiredArgsConstructor
@Getter
public class ShardingSphereRowData {
private final List < Object > row ;
}
内存中元数据的变化通过 event 发送,并同步到 zk 中,通过 zk 监听同步刷新其它节点的元数据库
利用 calcite 进行查询
增删改,通过内存对象操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
@Getter
public final class ShardingSphereData {
private final Map < String , ShardingSphereTableData > tableData = new LinkedHashMap <> ();
private ShardingSphereDataQueryEngine queryEngine ;
/**
* Query.
*
* @param sql sql
* @return result set
*/
public ResultSet query ( final String sql ) {
return queryEngine . query ( sql );
}
/**
* Register.
*
* @param metaData meta data
* @param eventBusContext event bus
*/
public void registerShardingSphereDataQueryEngine ( final ShardingSphereMetaData metaData , final EventBusContext eventBusContext ) {
ShardingSphereDataQueryEngine queryEngine = ShardingSphereDataQueryEngineFactory . getShardingSphereDataQueryEngine ();
// 注册到 calcite
queryEngine . init ( metaData , eventBusContext , tableData );
this . queryEngine = queryEngine ;
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
public class ShardingSphereDataFederationQueryEngine implements ShardingSphereDataQueryEngine {
private OptimizerContext optimizerContext ;
private ShardingSphereRuleMetaData globalRuleMetaData ;
private ConfigurationProperties props ;
private EventBusContext eventBusContext ;
private ShardingSphereMetaData metaData ;
private Map < String , ShardingSphereTableData > tableData ;
@Override
public void init ( final ShardingSphereMetaData metaData , final EventBusContext eventBusContext , final Map < String , ShardingSphereTableData > tableData ) {
this . optimizerContext = OptimizerContextFactory . create ( metaData . getDatabases (), metaData . getGlobalRuleMetaData ());
this . globalRuleMetaData = metaData . getGlobalRuleMetaData ();
this . props = metaData . getProps ();
this . eventBusContext = eventBusContext ;
this . tableData = tableData ;
this . metaData = metaData ;
}
@SneakyThrows
private Connection createConnection () {
MemorySchema memorySchema = new MemorySchema ( tableData , metaData . getDatabase ( "ShardingSphereData" ). getSchema ( "ShardingSphereData" ));
Properties info = new Properties ();
info . setProperty ( CalciteConnectionProperty . DEFAULT_NULL_COLLATION . camelName (), NullCollation . LAST . name ());
info . setProperty ( CalciteConnectionProperty . CASE_SENSITIVE . camelName (), "false" );
Connection result = DriverManager . getConnection ( "jdbc:calcite:" , info );
CalciteConnection calciteConnection = result . unwrap ( CalciteConnection . class );
SchemaPlus rootSchema = calciteConnection . getRootSchema ();
rootSchema . add ( "memory" , memorySchema );
return result ;
}
@SneakyThrows
@Override
public ResultSet query ( final String sql ) {
try ( Connection connection = createConnection ();
Statement statement = connection . createStatement ()) {
return statement . executeQuery ( sql );
}
}
@Override
public boolean isDefault () {
return true ;
}
}
use yaml to simulate ShardingSphere built in table
add ShardingSphere data and persist
add schedule thread or zk watch to trigger collect data
support to use federation to query shardingsphere data